Orgteh Blog
In-depth analysis of the latest AI research — with practical applications you can build on today.

2026-04-05
Stop Drowning in Agent Logs: A Lightweight Way to Surface the Trajectories That Actually Matter
Production LLM agents can generate tens of thousands of interaction traces per day. Most look identical: same tools, similar feedback, quiet success. Hidden inside are rare, messy failures—loops, mis-alignments, edge cas
2026-04-05
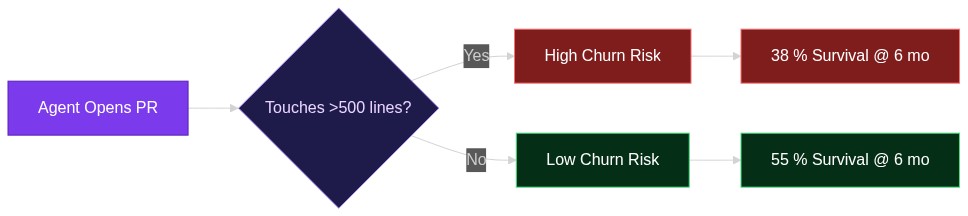
Autonomous Coding Agents in the Wild: What 110k Pull Requests Teach Us About AI-Generated Code That Lasts
Open-source repositories have a new contributor: the AI agent that opens pull requests, reviews code, and even argues in comments—no fingerprints on the keyboard. A recent study of 110,000 real-world PRs compared five ag

2026-04-03
From Silent to Curious: Teaching AI Coding Agents When to Ask Questions
Ever pushed a “quick” Jira ticket to an AI pair-programmer only to watch it confidently ship the wrong feature? The problem isn’t model size—it’s silence. Today’s coding agents are trained to act, not inquire. A fresh pr
2026-04-03
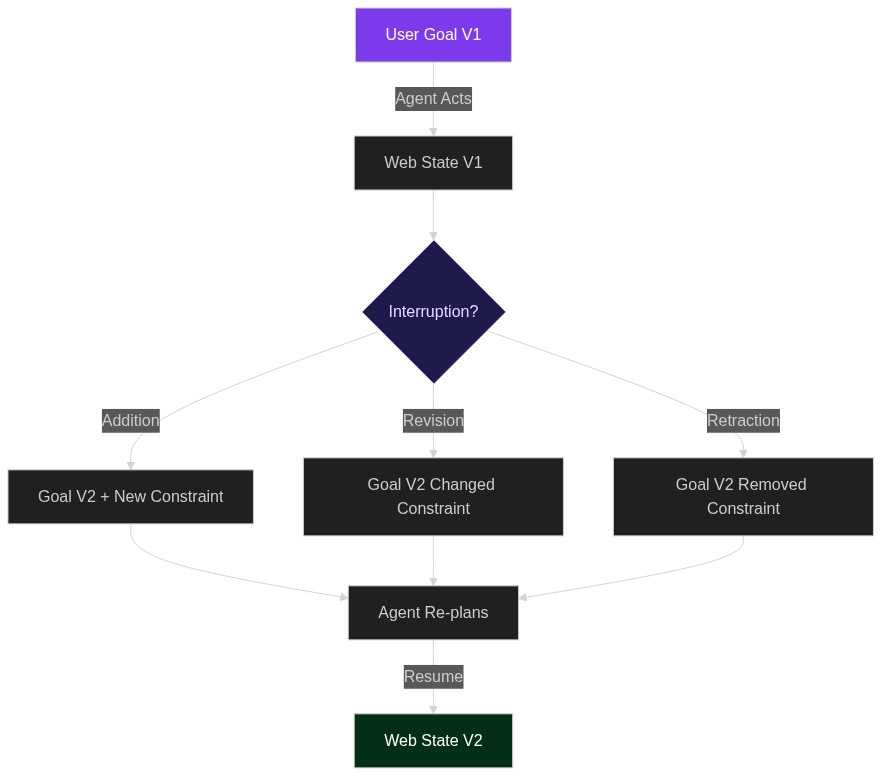
When Users Change Their Mind: Building Interruptible AI Agents That Survive Mid-Task Goal Changes
Imagine you’ve just deployed an LLM agent that books multi-city business trips. It’s halfway through reserving a flight, hotel, and rental car when the user messages: “Actually, skip the rental—I’ll use Uber, and upgrade

2026-04-02
From Idle to Instant: How “Eager” Hides Execution Latency in LLM Code Generation
Waiting for a 200-line Python script to finish generating before the first runs feels like watching paint dry. Today’s LLM coding agents—GitHub Copilot, ChatGPT Code Interpreter, your homemade ReAct loop—still follow a

2026-04-01
Think-Anywhere: How to Let Your Code-Gen LLM Pause, Reflect and Ship Better Code
Most “reasoning” models front-load all their brain-power: they think once, then spit out a long answer. That works for math puzzles, but real-world coding is messier—bugs appear only after 40 lines, edge cases hide insid
2026-03-31
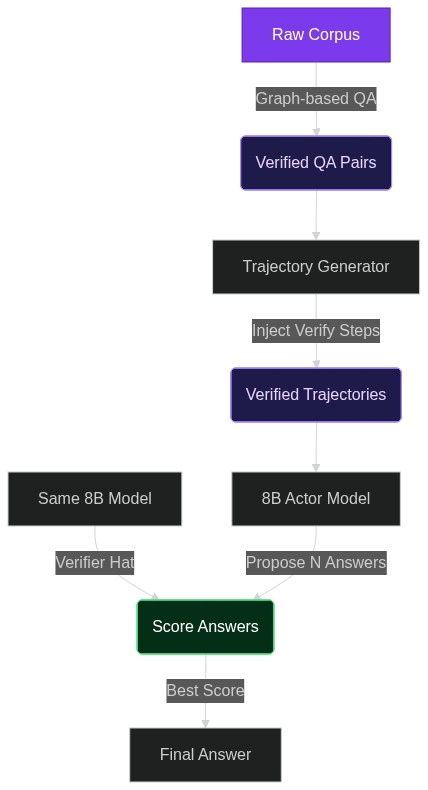
From 8B to 30B Performance: Building Deep Research Agents with a Verification-Centric Design
Open-ended research is the killer app for large language models, yet most home-grown agents collapse after three or four tool calls. The Marco DeepResearch paper (arXiv 2603.28376) shows the bottleneck isn’t model size—i
2026-03-31
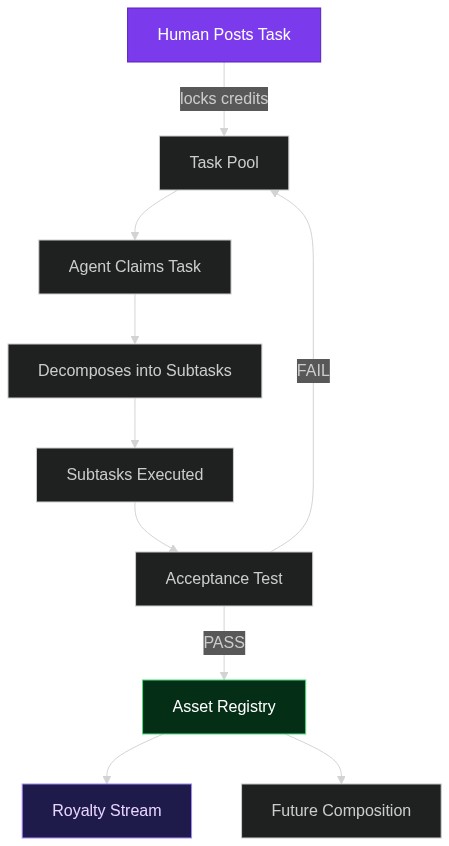
From Prompts to Civilization: How EpochX Turns AI Agents into a Self-Improving Economy
Most “AI agents” today are fancy wrappers around a single LLM call. EpochX, an open protocol described in a recent arXiv pre-print, treats every completed job as a Lego brick that future agents can snap into place—while

2026-03-30
Teaching LLMs to “Think Local”: How Online Repository Memory Turns Generic Coders into Project-Native Contributors
New research shows how AI agents can learn project-specific conventions by replaying past commits, dramatically improving pull-request acceptance rates.

2026-03-30
From Hard-Wired to Human-Readable: How Natural-Language Agent Harnesses Let You Swap LLMs Without Rewriting Code
Agent builders face a paradox: the smarter the agent, the more its “brains” are tangled inside controller code, framework glue, and vendor-specific SDKs. Swapping GPT-4 for Llama-3 can take a week of refactoring; A/B-tes
2026-03-29
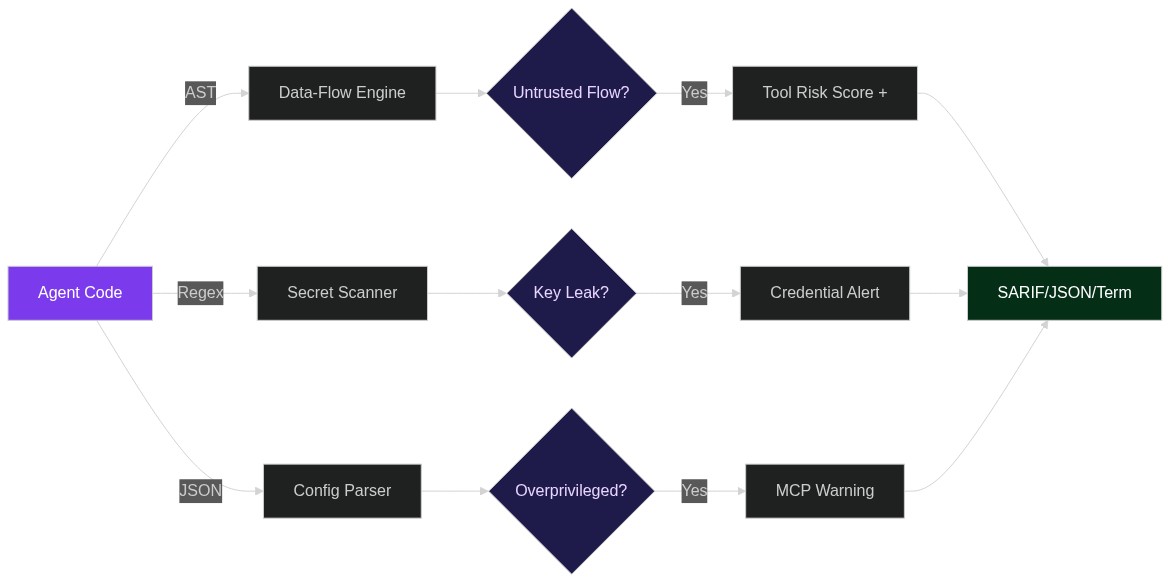
Stop Shipping Swiss-Cheese Agents: How “Agent Audit” Finds 40/42 Real-World LLM Vulnerabilities in <1 s
You just wired the last tool function, the agent passes the smoke test, and the PM wants a prod URL. Did you verify that the cute tool won’t when the model has a bad day? Most teams don’t, which is why agents leak keys
2026-03-29
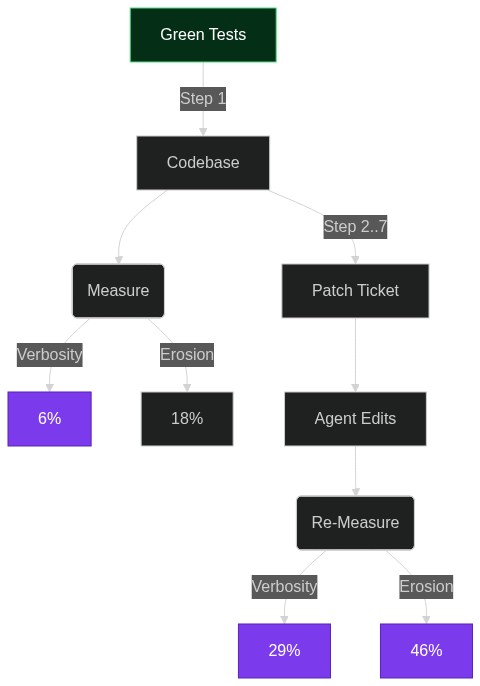
Why Your AI Coding Agent Quietly Turns to Slop—And How to Measure It Before It’s Too Late
Every week a new model tops the coding leaderboard, yet anyone who ships real software knows the dirty secret: the code that passes today’s unit tests can become tomorrow’s maintenance nightmare. SlopCodeBench, a new ope