Orgteh Blog
In-depth analysis of the latest AI research — with practical applications you can build on today.

2026-05-02
Claw-Eval-Live: The First Benchmark That Forces LLM Agents to Prove They Actually Did the Work
Most leaderboards feel like time capsules: a frozen set of questions, a single “best” answer, and a score that never changes after publication.

2026-04-29
From One Bit to Bullet-Proof Rules: Teaching LLM Agents Safety with Nothing but a Blinking Danger Light
Imagine dropping a fresh LLM agent into a maze where every wrong step could blow up the level. You can’t tell it the rules, you can’t give it a reward function, and the only feedback you ever get is a tiny red LED that f

2026-04-28
Memanto: The Lightweight Memory Layer That Makes AI Agents Remember Like Humans
If you’ve ever built an AI agent that needs to survive more than one chat session, you know the pain: vector databases balloon in size, graph queries grind to a halt, and your cloud bill looks like a phone number. Memant
2026-04-28
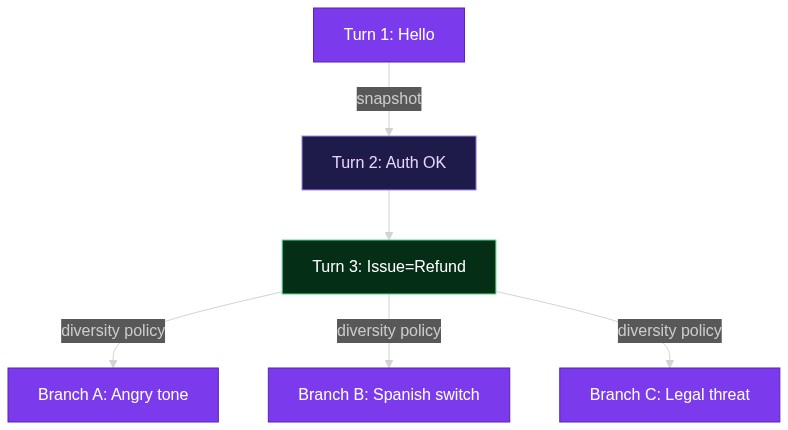
Stop Wasting Tokens: How DIVERT Finds LLM-Agent Bugs 3× Faster Than Monte-Carlo Rollouts
If you’ve ever tried to evaluate an AI agent that chats with customers for more than two turns, you know the pain: you burn thousands of dollars on GPT-4 to simulate conversations, yet the same “Hi, I need help” prefix i

2026-04-27
From 128 K to 36 M Tokens: How SLIDERS Makes Any Document Set Feel Tiny
If you’ve ever watched a RAG pipeline slow to a crawl when the legal team drops 3 000 PDFs on you, you already know the dirty secret of “long-context” LLMs: the window is never long enough. Frontier models advertise 128

2026-04-25
From Static to Smart: Building Self-Evolving Memory for LLM Agents That Actually Works
Imagine your AI assistant remembers that you hate cilantro, prefer JSON over YAML, and once debugged a memory leak in a Go microservice—then uses that knowledge to speed up every future request. That’s the promise of LLM

2026-04-24
From Chat History to Living Memory: How PersonalAI Builds Knowledge-Graph Agents That Actually Remember You
Most LLM agents treat memory like a scratchpad—everything fades once the context window slides forward. PersonalAI (arXiv 2506.17001) replaces the scratchpad with a self-updating knowledge graph that acts as a long-term,

2026-04-24
LLM-Redactor in Action: 8 Battle-Tested Ways to Ship AI Agents Without Leaking Secrets
Every time your coding copilot, support bot, or analytics agent calls a cloud LLM, it ships a tiny data-dump of your world: customer names, proprietary algorithms, hard-coded secrets, the lot. Once the packet leaves your

2026-04-23
Stop Drowning Your Terminal Agent in Tokens—Meet TACO, the Self-Evolving Compressor
Every time your AI agent types , , or , the terminal spits back a fresh wall of text. Keep every byte in the prompt and the token bill explodes quadratically—100 steps cost 10 k tokens, 200 steps cost 40 k, and by step 5
2026-04-23
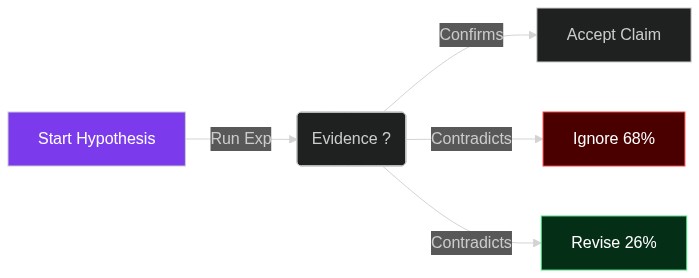
AI Scientists That Don’t Reason: What 25,000 Agent Runs Teach Us About Building Reliable LLM Research Pipelines
If you paste a glowing result into Slack without reading the trace, you may already be shipping “science” that no human ever sanity-checked. A sobering pre-print dropped last week: researchers ran 25,000 autonomous LLM a

2026-04-23
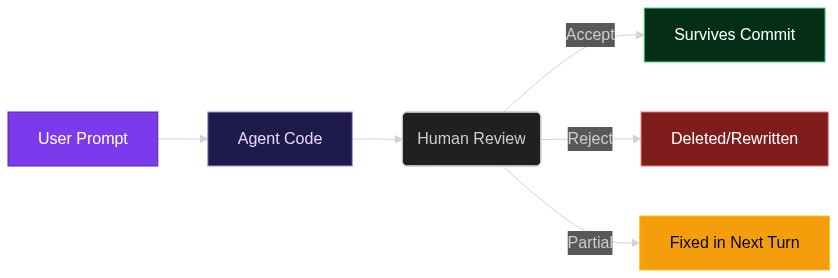
From Chat to Click: How Chat2Workflow Turns Plain English into Deploy-Ready Visual Workflows
Imagine opening Slack, typing “When a high-value customer submits a ticket, look up their Stripe history, draft a personalized apology email, and open a Jira bug if the amount is >$1 k,” then watching a live diagram appe
2026-04-23
SWE-chat: What 6,000 Real-World Coding Sessions Teach Us About AI Agents in the Wild
If you’ve ever wondered whether your AI coding assistant is actually helping—or just generating fancy-looking garbage—you’re not alone. Despite the hype, we’ve had shockingly little hard data on how developers really use