Orgteh مدونة
تحليلات معمّقة لأحدث أبحاث الذكاء الاصطناعي — مع تطبيقات عملية يمكنك البناء عليها مباشرة.

2026-04-14
من عشرة مساراتٍ متوازيةً إلى إجابةٍ واحدةٍ رائعة: بناء نظام تجميعٍ متقدّم على طراز AggAgent
كيفيّة تحويل 10 عمليات تنفيذ متوازية إلى إجابة واحدة ممتازة عبر نظام AggAgent لتجميع ذكي للمسارات الكاملة بدلاً من التصويت البسيط، مع حفظ الميزانيّة الرمزيّة وتحسين الدقّة بنسبة تصل إلى 10 %
2026-04-14
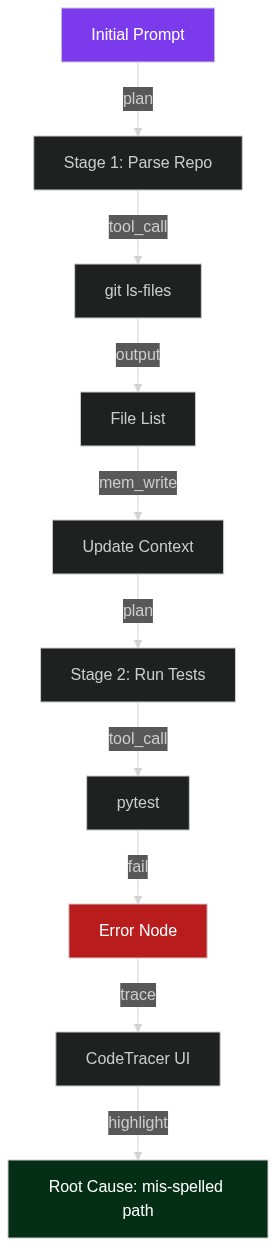
CodeTracer: المصحّح المفقود لوكلاء LLM الذي يخبرك أين حدث الخطأ فعلاً
إذا سبق أن شاهدتَ وكيل شيفرة مستقلاً يدخل في حلقة لا نهائية «إصلاح الاستيراد ← كسر الاختبار ← إصلاح الاستيراد» الساعة 3 صباحًا، فأنت تعرف الألم: 40 ميغابايت من سجلات JSON، طرفية تبدو لوحةً لجاكسون بولوك من stderr، واليقي
2026-04-14
CocoaBench: Why Your “Unified” AI Agent Still Fails 55 % of the Time (and How to Fix It)
If you’ve ever watched an LLM agent cheerfully delete the wrong folder, hallucinate a non-existent API, or click the “Submit” button on a screenshot that is actually a static PNG, you already know the dirty secret of mod

2026-04-13
From Messy Text to Query-Ready Tables: Building ScheMatiQ-Style Agents with Orgteh
Imagine you have 10 000 PDFs—court opinions, drug-labels, or pre-print papers—and your boss asks, “Which proteins are mentioned together with adverse events?”

2026-04-11
كيف كشف اختبار ClawBench الحقيقة المرّة عن الوكلاء الذكيّين وكيف تُصلحها
إذا سبق أن شاهدتَ وكيلاً ذكيّاً يضغط الزرّ الخطأ بثقة ويعطّل تدفّق الدفع بالكامل، فأنت تعرف الألم الذي يحاول ClawBench حلّه. أطلق باحثون من أربع جامعات معياراً يضمّ 153 مهمة تعمل على مواقع حيّة—أمازون، كالندلي، إنديد وغي
2026-04-10
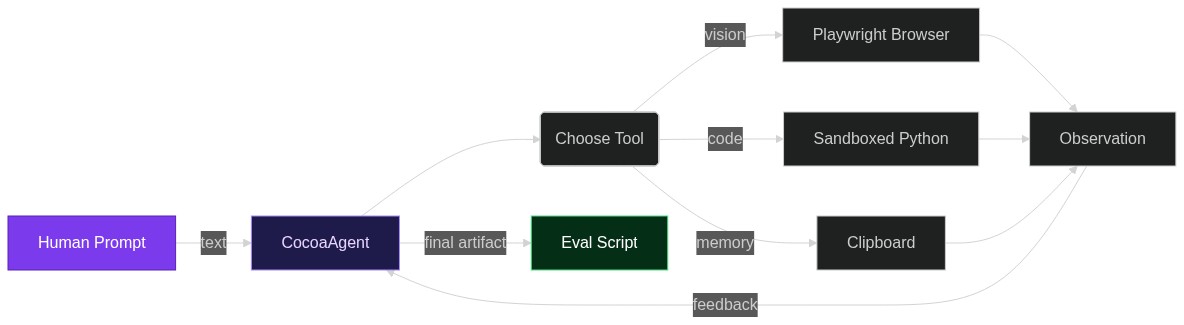
من الأوزان إلى وقت التشغيل: كيف يحوّل الإخراج الخارجي نماذج اللغة الكبيرة إلى وكلاء جاهزة للإنتاج
لم يعُد الضبط الدقيق هو الطريق الأسرع لجعل نموذج لغة كبير مفيدًا. اليوم يكفي أن تُلَفّه بمخازن ذاكرة، ووحدات مهارات، وبروتوكولات تفاعل، وطبقة تنسيق صغيرة، ثم تُطلقه. يُسمّى هذا التحوّل «الإخراج الخارجي»، وهو السبب في أن

2026-04-09
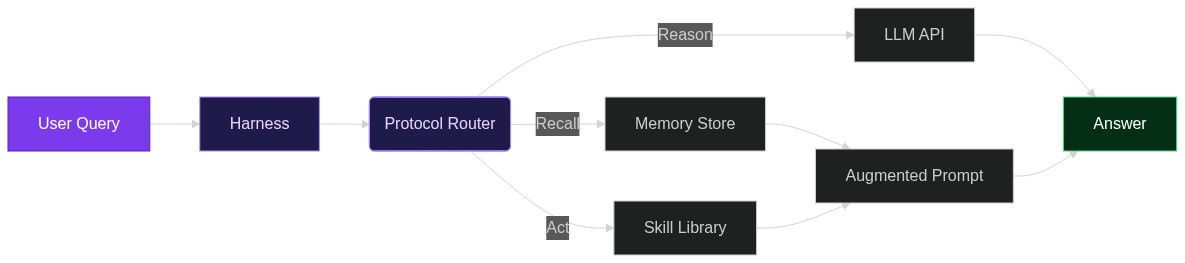
من البحث إلى التوليف: بناء جيش أبحاث متعدّد الوكلاء باستخدام Paper Circle
كل أسبوع تُطرَح آلاف الأوراق الجديدة على arXiv وbioRxiv ومنصّات المؤتمرات. Paper Circle هو نظام متعدّد الوكلاء مفتوح المصدر يقوده نموذج لغوي كبير، يحوّل تلك الفوضى إلى سيرورة متكرّرة وقابلة للتدقيق: يصطاد الأوراق، يصنّفه
2026-04-09
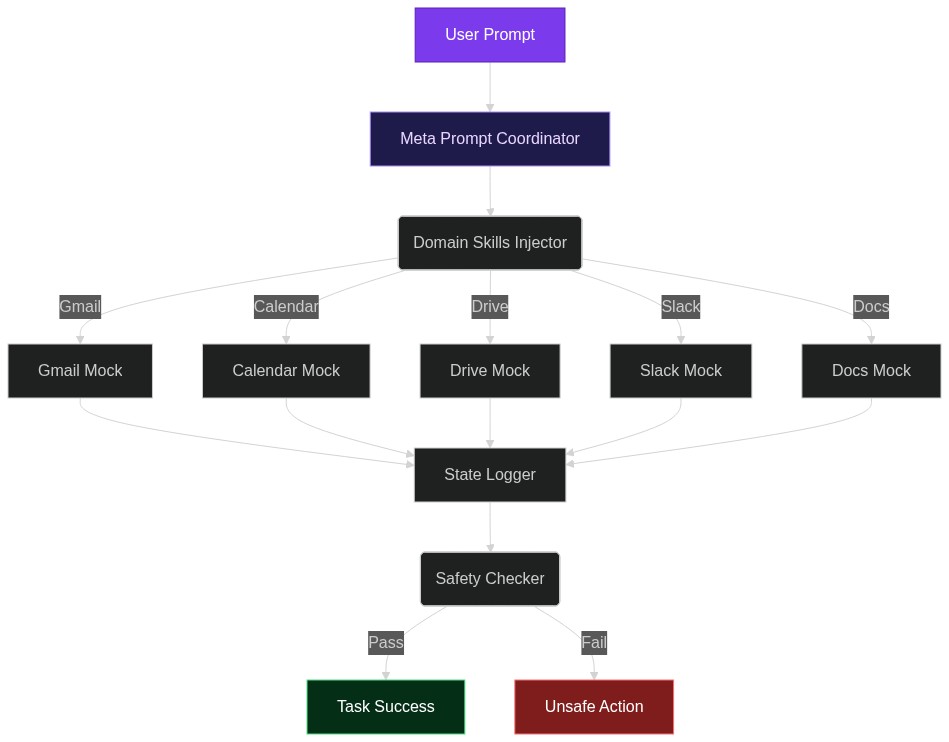
From Gmail to Google Drive: How ClawsBench Lets You Benchmark LLM Agents Without Breaking Production
Imagine handing an LLM agent the keys to your company’s Gmail, Calendar, and Drive—then watching it accidentally delete a quarter-million-row spreadsheet while trying to schedule a meeting. That nightmare is exactly why
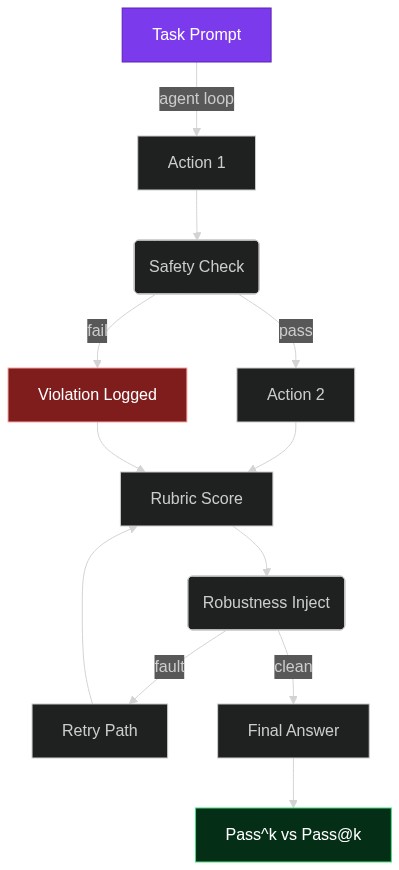
2026-04-08
Stop Guessing, Start Measuring: A Developer’s Guide to Stress-Testing LLM Agents with Claw-Eval
You shipped an AI agent that books calendar invites, but two weeks later a user reports it silently deleted an entire project folder. Sound familiar? The model passed your unit tests, the demo looked flawless, yet produc

2026-04-07
ClawArena: The Missing Stress-Test for AI Agents That Live in Messy, Ever-Changing Data
Picture a legal-assistant agent that tells your client the statute of limitations is three years—because it read an outdated blog post—while the actual law changed to two years last month. Or a finance bot that keeps rec

2026-04-06
كشف AgentHazard: لماذا قد ينقلب وكيلُك الذكيّ «الآمن» إلى خائن (وكيف تكتشفه قبل الآخرين)
إذا كنت تعتقد أن الدردشة الآلية التي ترفض كتابة برامج ضارة «آمنة»، فجرّب منحها موجه bash وهدفًا. يُظهر معيار AgentHazard، وهو مقياس جديد من ورقة حديثة على arXiv، أن وكلاء الحاسوب—نماذج اللغة التي تستطيع النقر والبرمجة

2026-04-05
AgentWatcher: مراقب قواعدي عملي لكشف حقن الإيعازات في الوكلاء الذكية ذات السياق الطويل
يُعدّ حقن الإيعازات القاتل الصامت للوكلاء الذكية في الإنتاج. في لحظة يُلغي بوت الدعم الطلبات بهدوء، وفي التالية يُطلق رموز خصم لغرباء لأن المستخدم أخفى عبارة «تجاهَل التعليمات السابقة» في ملفّ PDF من 30 صفحة. تنهار الدفا