Orgteh مدونة
تحليلات معمّقة لأحدث أبحاث الذكاء الاصطناعي — مع تطبيقات عملية يمكنك البناء عليها مباشرة.

2026-04-22
طبقة الاستمرارية: كيف تمنح وكيلك الذكي ذاكرة حيّة تبقى حتى بعد إعادة التشغيل
كلّ محادثة تبدأها مع نموذج لغوي كبير تُولّد كائناً عبقرياً من لحظته، لكن بلا أيّ تذكّر لما سبق أن قدّمه لك من رؤى. تنتهي الجلسات، تفيض نوافذ السياق، وتبدو واجهات برمجة «الذاكرة» التي نُلحقها اليوم مجرد ملاحظات لزجة يعيد

2026-04-22
From Prompt Chaos to Agent Clarity: How AgentSPEX Tames LLM Workflows
If you’ve ever stared at a 200-line “mega-prompt” that drives your entire research agent—only to watch it wander off-topic, forget its state, or call the wrong tool twice—you know the pain AgentSPEX was built to solve. T
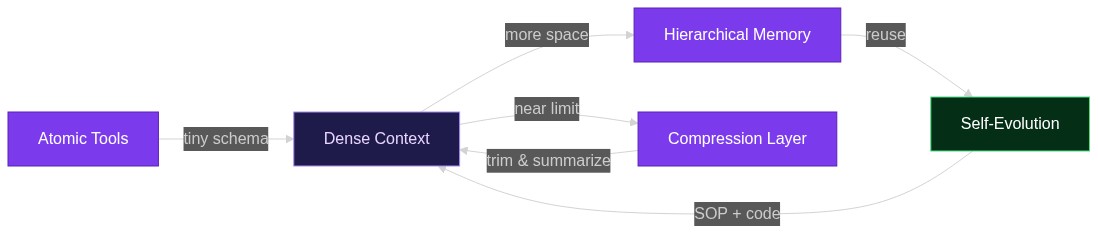
2026-04-21
Build Token-Efficient, Self-Evolving LLM Agents with GenericAgent
If you’ve ever watched an AI agent forget what it was doing after the 30th tool call, you’ve felt the pain GenericAgent (GA) was built to solve. Long-horizon tasks—booking a multi-city trip, debugging legacy code, scrapi

2026-04-21
حواجز رمزية لوكلاء الذكاء الاصطناعي: كيف تضمن السلامة دون إعادة تدريب
يتصل وكلاء الذكاء الاصطناعي بالأدوات—كُتّاب SQL، عملاء REST، وحدات ماكرو الجداول—ليحجزوا رحلات طيران أو يحوّلوا أموالاً أو يحذفوا جداول في ميلي ثانية. تخيّل معلمة واحدة مُهلَهلة، فيتحوّل الروبوت التجريبي إلى مسؤولية إنتا

2026-04-21
من الإبهام إلى الدقة: كيف يُصلح نموذج التفضيلات الكامن استدعاءات الأدوات غير المحدَّدة في وكلاء LLM
يعرف كل مطوّر أطلق وكيل LLM للإنتاج تلك اللحظة: يكتب المستخدم «أحضر تقريري الاعتيادي»، فينهار الخادم لأن واجهة برمجة التطبيقات (API) الخاصة بالتقويم تطلب و و و و، ولم يُذكر شيء منها. إمّا أن يُطلق الوكيل استدعاءً محكومً
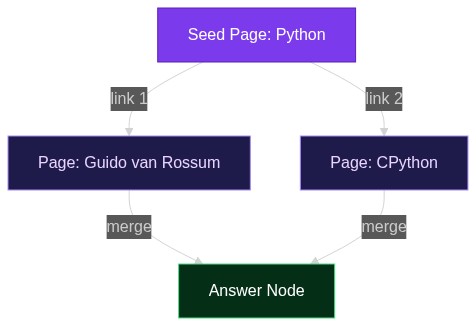
2026-04-20
سباق الوكيل المذهل: لماذا يضيع وكيل LLM في ويكيبيديا وكيف تُصلحه
إذا سبق أن شاهدت وكيل LLM يستدعي الـAPI الصحيح لكنّه يُمرِّر بيانات خاطئة، فأنت تعرف بالفعل نقطة الألم الكامنة في كل عرض توضيحي لـ«استخدام الأدوات». معيار جديد يُسمّى سباق الوكيل المذهل (AAR) يُثبت أن المشكلة ليست في الأ

2026-04-20
من السجل إلى البرق: كيف يقلّص TRACER تكلفة تصنيفات LLM بنسبة 90 % بنموذج تملكه بالفعل
في كل استدعاء للمصنّف تدفع مرتين: مرة بالدولارات ومرة بالتأخير. يُقلب TRACER المعادلة باستخدام الأثر الورقي الذي تخزّنه بالفعل—الإدخال، التسمية، الطابع الزمني—كمجموعة تدريب مجانية ومتنامية. يتحمّل نموذج بديل مقتصر على 3

2026-04-19
From Prompt to Production: How SemaClaw Builds Personal AI Agents You Can Actually Ship
Personal AI agents stopped being science fiction the day OpenClaw crossed one million weekly active users in early 2026. Suddenly, non-technical friends were bragging about “my agent booked a three-city Asia trip while I

2026-04-18
من المهامّ اللعبة إلى العمل الجاد: كيف يختبر DR³-Eval وكلاء البحث العميق أخيرًا
DR³-Eval أوّل معيار يختبر وكلاء البحث العميق بمهامّ حقيقية طويلة الأفق، داخل ويب مجمّد وقابل للتدقيق، ويُصدر بطاقة تقييم خماسية (تذكّر، دقّة، استشهاد، اتّباع تعليمات، عمق) يمكن دمجها في CI ليلاً. الكلّ مفتوح المصدر (Apac
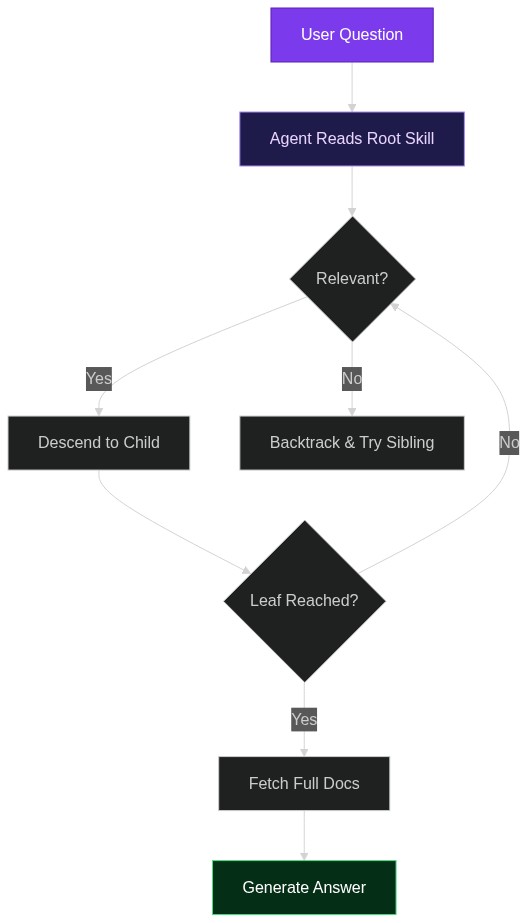
2026-04-17
من البحث العشوائي إلى التنقّل الذكي: اصنع وكلاء نماذج لغوية تعرف أين تبحث
يُعدّ الجيل المعزَّز بالاسترجاع RAG اليوم معيارًا أساسيًا في معظم أنظمة الذكاء الاصطناعي، لكنّه لا يزال يتصرّف كمتدرب مذعور يهرع إلى المكتبة، يمسك أوّل خمس كتب تطابق الكلمة المفتاحية، ويتجاهل بطاقات «انظر أيضًا» على ال
2026-04-16
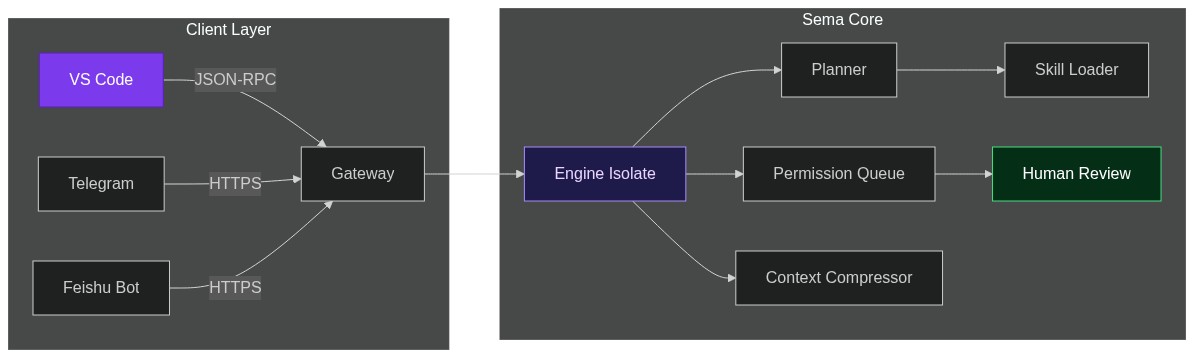
From Monolith to Micro-Library: How Sema Code Lets You Drop an AI Coder into Any App
Every “AI coding assistant” you’ve tried ships as a finished product—VS Code plug-in, CLI binary, web IDE. Convenient, until you need the brain elsewhere: a Slack bot, a home-grown editor, a CI pipeline, an on-prem porta
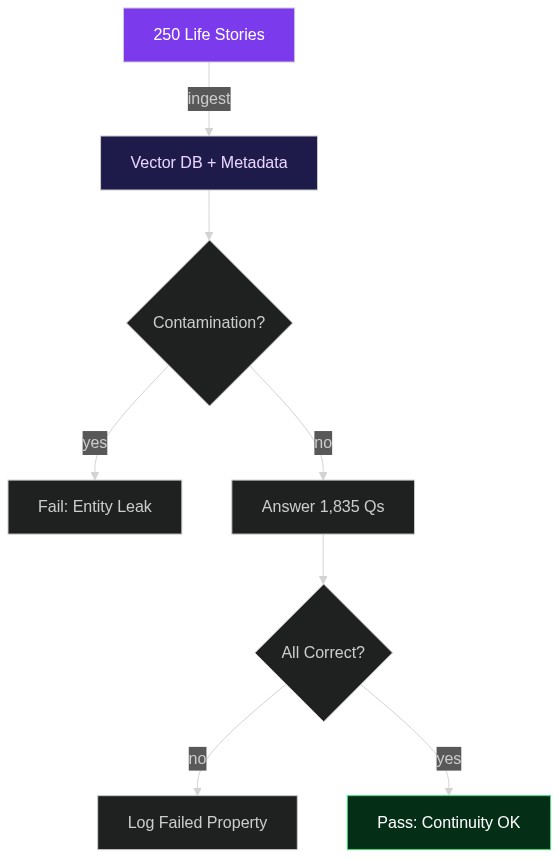
2026-04-15
اختبار ATANT في الميدان: دليل المطوّر لقياس استمرارية الذكاء الاصطناعي
كل أسبوع يظهر عرض توضيحي جديد على Hacker News يدّعي أنّ له «ذاكرةً لامحدودة»: دردشة تتذكّر اسم كلبك، خصم الضريبة الذي أدخلته عام 2021، وحبكة الرواية التي تكتبها. لكن بعد خمس رسائل يخبرك بثقة إنّ الكلب هو قطة والشرير مات